






Для многих представителей корпоративного заказчика то, что происходит внутри искусственного «сознания» остается тайной. В свою очередь это порождает неверные предпосылки и ожидания от проектов с применением технологий ИИ. Мы постараемся доступно объяснить принципы работы ИИ и машинного обучения на примере его применения в технологиях распознавания и анализа речи и голосовой биометрии.
Если сравнивать чистый звук от камертона с ровными кругами от брошенного в воду камня, то человеческая речь – это волнение на озере, где поверх больших волн могут накладываться волны поменьше и даже рябь от ветра. Так вот, каждый произносимый человеком, знакомый нам звук - это набор звуковых волн, каждая из которых характеризуется своей амплитудой и частотой. Или, иными словами, громкостью и тоном.
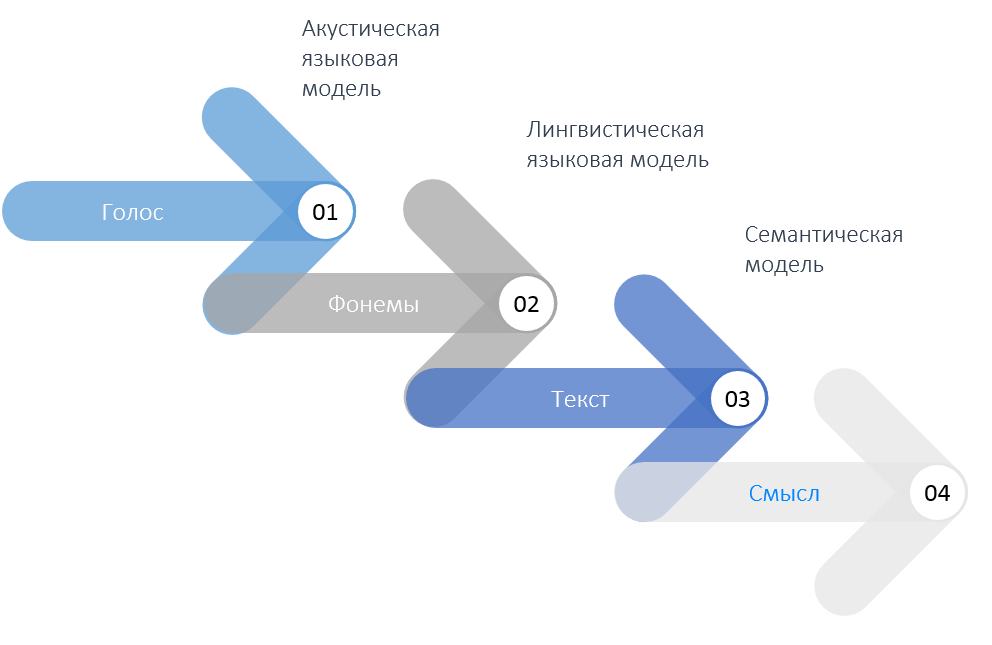
Акустическая модель: услышать звук
Технология распознавания речи предусматривает обработку получаемой с помощью микрофона информации о колебаниях воздуха в несколько этапов. В первую очередь все эти колебания разбиваются на типичные, характерные фонемы. Фонема – не буква, а звук, или даже кусочек звука. Причем для каждого языка - русского, английского или любого другого - характерен свой набор фонем. Чем языки ближе, тем больше эти фонемы пересекаются. Но как, например, в английском языке не встречается звук «Ы», так в русском нет звука «TH». Базу данных тех фонем, которые компьютер ищет среди звуковых колебаний, мы называем акустической языковой моделью. Каждому слову соответствует определенный набор фонем. Учитывая, что разные люди говорят немного по-разному, этот набор может быть не один, а несколько. Например, звуки, произносимые детьми или женщинами, будут отличаться от тех, что произносят мужчины. Именно поэтому соответствие «слово – фонемы» не строгое, а имеет определенную гибкость, подкрепленную данными о наиболее вероятных соответствиях.
Для обеспечения наилучшего качества мы постоянно работаем над улучшением наших базовых моделей. Сейчас поддерживается несколько языков. Модель для русского – одна из лучших. В платформе BSS.Speech используется специальная нейронная сеть, которая определяет наиболее вероятные фонемы человеческой речи. Для корректного обучения этой сети используются подходы глубокого машинного обучения - Deep Learning. Для обеспечения наивысшей точности на создание и улучшение базовых моделей мы арендуем значительные вычислительные мощности, чтобы предоставить нашим клиентам наилучший результат и максимальную точность.
А что делать с акцентом?
У наших клиентов часто возникают вопросы, связанные с тем, насколько хорошо система будет понимать речь с акцентом. Ведь акцент – это не что иное, как произнесение слов чужого языка с использованием фонемного состава родного. Однако благодаря технологиям машинного обучения акустическая модель не является неким эталоном, который создается один раз и используется всегда, везде и во всех случаях. Эта модель может обучаться и адаптироваться. Для обучения используются аудиозаписи – эталонные текстовые транскрипции, сделанные человеком. Эти данные используются для дополнительного обучения нейронной сети. Нейронные связи немного корректируются, и специфичные для акцента фонемы становятся понятными для искусственного интеллекта. Таким образом, если мы знаем о том, что решение будет использоваться в регионах с характерным говором, мы можем адаптировать акустическую языковую модель под пользователей. Разумеется, данное описание не отражает всех сложностей технологии. В процессе машинного обучения используются довольно сложные подходы, именуемые кросс-вариацией и анализируются специальные метрики, позволяющие оценивать и оптимизировать качество моделей на нескольких итерациях. Это позволяет добиться намного более качественного результата, чем просто обучения без последующего анализа его результатов.
Лингвистическая модель: разбираем слова
Однако разбора речи на фонемы еще недостаточно, чтобы понять человеческую речь и обратить ее в текст. Наверняка каждый попадал в ситуацию, когда он или она не могли расслышать часть сказанного собеседником, но по смыслу предложения были способны понять сказанное. Примерно то же самое делает и машина. Одному и тому же набору фонем в языке может соответствовать сразу несколько слов. Например, фонемный состав слов «меч» и «мяч» будет очень схож. Компьютер же никогда не знает наверняка, какой звук он услышал. С вероятностью 71% он определил слово «меч» и с вероятностью 74% «мяч». На этом этапе в игру вступает лингвистическая модель. Она представляет собой огромный словарь, состоящий из слов и словосочетаний. Парные сочетания слов называются диаграммами, сочетания по три слова – триграммами. Каждому сочетанию в соответствие поставлена некоторая величина, которая характеризует то, насколько часто эти слова в естественной речи человека встречаются рядом друг с другом. Например, лингвистическая модель может сказать компьютеру о том, что словосочетание «мяч рубил врагов» в речи человека встречается намного реже, чем «меч рубил…». Компьютер, используя лингвистическую модель, анализирует возможные сочетания слов и выбирает те, которые в большей степени соответствуют как фонемному составу, так и вероятности их нахождения в таком сочетании в этой части предложения. Таким образом, решение и определяет, что же именно было сказано человеком.
Платформа BSS.Speech использует обширную и исчерпывающе полную акустическую модель русского языка. Эта модель прекрасно зарекомендовала себя на практике: в пилотных проектах в различных регионах России, где так называемый «говор» может довольно сильно отличаться, и в Белоруссии, где, несмотря на широкое употребление русского, встречается смешение языков, так называемая трасянка.
Специфическая профессиональная терминология
Другим вопросом, которым часто задаются наши клиенты, является способность машины разбирать речь, специфичную для определённой области знаний. Действительно, если взять общую языковую модель и попробовать использовать ее для распознавания речи, например, медицинского специалиста, мы увидим, что многие слова угадываются неверно. Это одна из причин, по которым корпоративные заказчики с неохотой идут на использование публичных облачных сервисов распознавания речи. При использовании в специфичных областях с устоявшейся терминологией эти сервисы применяют общеязыковые модели и не всегда могут показать удовлетворительную точность распознавания. Мы в свою очередь предлагаем клиентам выполнить обучение лингвистической языковой модели на их данных. Поскольку лингвистическая модель уже не содержит в себе информации о звуке, а только информацию о вероятных словах, диаграммах, триграммах и их последовательностях, для обучения этой модели достаточно использовать тексты из специфичной области, сочетания слов, соответствующие терминологии специалистов, чью речь мы собираемся анализировать.
В заключение хочется сказать, что технологии применения машинного обучения и искусственного интеллекта на этом не останавливаются. Для извлечения смысла сказанного из распознанной речи или интента, как его еще называют, также используются специальные механизмы, называемые семантическими статистическими моделями. Кроме интентов или намерений, из речи говорящего можно извлекать так называемые «сентименты» или маркеры эмоциональной окраски. Это решение Компания BSS планирует скоро выпустить на рынок. Для более качественного вычисления эмоциональной окраски платформа BSS.Speech использует каскадный метод анализа, но это уже тема для отдельного разговора.
Лучшие новости сегодня
Вы искали сегодня
Другие новости сегодня
Закон об открытых API рассчитывали принять в 2025 году, а обязательный запуск начать в 2026-м. Сейчас требования по обмену данными остаются добровольными, что создает риски несовместимости решений и размытой ответственности. Ассоциация...
Курс доллара США, устанавливаемый Центральным банком РФ, на 18.07.2026 г. составит 78,3987 руб. Это на 8,1 коп. выше, чем курс, действующий сегодня. Официальный курс Евро на завтра составит ...
НАЛОГИ, БУХУЧЕТ Минфин обсудил с бизнесом исключение торговли из льгот по УСН - из списка видов деятельности, для которых регионы могут вводить льготные ставки > Единый государственный реестр...[/h]
Центробанк России объявил официальный курс доллара США на завтра, 16.07.2026. Курс составит 77,9568 руб. Это на 46,6 коп. выше, чем курс, действующий сегодня. Официальный курс Евро на завтра составит ...
Согласно проекту постановления клиент обратится с заявление о возврате в банк. Тот проверит себя, и если решит, что все сделал, как положено, перенаправит заявление оператору связи. Тот проверит, от кого пропускал...
Однако авторам рекомендовано дописать получение информации о таких поступлениях инспекциями ФНС. Правительство намерено в целом поддержать депутатский законопроект с поправками в закон 173-ФЗ «О валютном регулировании...
«Наши задачи» - предоставлять самую оперативную, достоверную и подробную информацию по банковскому рынку; - помогать клиентам в выборе самых выгодных банковских продуктов; - способствовать банкам в поиске качественных клиентов; - налаживать общение между банками и их клиентами.
Закон об открытых API рассчитывали принять в 2025 году, а обязательный запуск
Подробнее
Курс доллара США, устанавливаемый Центральным банком РФ, на 18.07.2026 г.
Подробнее
НАЛОГИ, БУХУЧЕТ Минфин обсудил с бизнесом исключение торговли из льгот по УСН
Подробнее
Центробанк России объявил официальный курс доллара США на завтра, 16.07.2026.
Подробнее
Согласно проекту постановления клиент обратится с заявление о возврате в банк.
Подробнее
Однако авторам рекомендовано дописать получение информации о таких
ПодробнееЭкономика сегодня

ЦБ установил официальные курсы валют на 4 сентября. Рубль падает ко всем основным зарубежным валютам....
Подробнее
Российская валюта снижается ко всем основным мировым валютам. Официальный курс ...
Подробнее
💸 Ежедневный совет Банки — короткий и полезный совет, который помогает управлять деньгами осознанно. Подготовка к школе всегда...
Подробнее
Спрос на страховые полисы на случай онкологических заболеваний за год вырос на 40%. Об этом сообщил «Росгосстрах», проанализировав темпы роста продаж полисов данного сегмента. Больше всего спрос увеличился...
Подробнее
💸 Ежедневный совет от Банки — просто о том, как повысить эффективность сбережений. Если вы вносите на счет крупные суммы наличными,...
Подробнее
Российская валюта подешевела к доллару, евро и юаню. Официальный курс доллара, установленный Центробанком на 30 августа 2025 года, составляет 80,3316 рубля (прежнее значение — 80,2918 рубля), официальный...
Подробнее
Закон об открытых API рассчитывали принять в 2025 году, а обязательный запуск начать в 2026-м. Сейчас требования по обмену данными остаются добровольными, что создает риски несовместимости решений и размытой ответственности. Ассоциация...
ПодробнееКурс валют сегодня
Комментарии (0)